多表查询用什么联接?别信感觉,用数据说话
时间:2020-08-31来源:www.pcxitongcheng.com作者:电脑系统城
我们在做SQL查询的时候,经常会用到各各种关联查询,对于不同的联接,效率还是有差别的,具体该用哪种呢?虽说数据库会做一些查询的优化,但了解原理,能有助我们直指核心。
开始join吧。

我们分析三种常见的join: Merge join,Hash join 和 NestedLoop Join。在此之前,我们先介绍一些关键词:
Inner ralation 和 outer relation。
一个 relation 可以是:
- 一张表
- 一个索引
- 一个前面操作的中间结果
当你在对两个 relation 进行 Join 的时候,join 算法对inner 和 outer relation 的方式是有区别的。outer relation 是左数据集, inner relation 是右数据集。
比如说 A JOIN B,此时 A 是 outer relation,B 是 inner relation。而且一般 A JOIN B 和 B JOIN A 用时是不一样的。
后面我们假设 outer relation 有 N 个元素, inner relation 有 M个元素。不过实际的优化器里,可以从统计信息中拿到确切的值。
Nested loop join

嵌套关联是最容易的一个。过程大概是:
遍历 outer relation 的每一行
然后去查找inner relation 的每一行是否匹配
写成伪代码是这样:
- nested_loop_join(array outer, array inner)
- for each row a in outer
- for each row b in inner
- if (match_join_condition(a,b))
- write_result_in_output(a,b)
- end if
- end for
- end for
因为两重遍历,所以复杂度是 O(N*M)。对应到磁盘的I/O,在outer relation中,N 行中的每一行,都需要从inner relation 中循环读取M行数据。
所以这个算法需要从磁盘读 N + N*M行数据。但是,如果 inner relation 足够小,可以放到内存里的话,就只需要读 M + N 次了。虽然说在时间复杂度上没什么变化,但在磁盘I/O上这个方式还不错,因此, inner relation 可以被索引替代,磁盘I/O也更有利。
Hash join
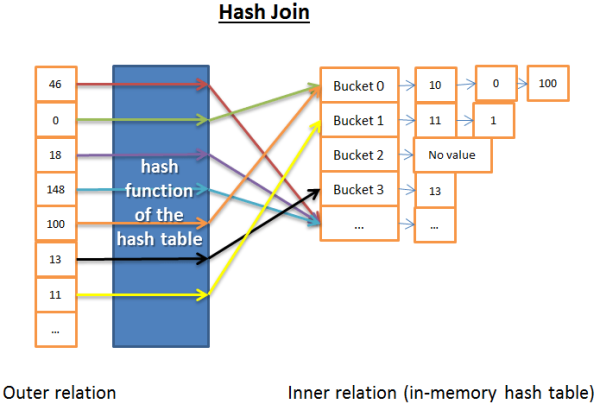
哈希连接更复杂,不过很多时候也比循环嵌套连接成本要低
哈希连接的原理是:
- 从 inner relation 中获取所有元素
- 保存哈希表到磁盘
- 在内存中建立一个哈希表
- 逐条读取outer relation 的所有元素
- (用哈希表的哈希函数)计算每个元素的哈希值,来查找inner relation 关联的哈希桶
- 查看 outer relation 的元素是否有哈希桶内的匹配。
在时间复杂度方面我们需要做点假设简化问题:
- inner relation 被划分成 X 个哈希桶
- 哈希函数接近均匀地分布每个 relation 内数据的哈希值,相当于说哈希桶大小是一致的。
- outer relation 的元素与哈希桶内的所有元素的匹配,成本是哈希桶内元素的数量。
时间复杂度是 (M/X) * N + cost_to_create_hash_table(M) + cost_of_hash_function*N。如果哈希函数创建了足够小规模的哈希桶,那么复杂度就是 O(M+N)。
还有个哈希联接的版本,对内存更友好,但是对磁盘 I/O 不够有利。情况是这样的:
- 计算outer relation 和 inner relation 双方的哈希表
- 保存哈希表到磁盘
- 然后逐个比较两个 relation 的哈希桶(一个关系读到内存里,另一个逐行读取)
Merge join
合并联接是唯一产生排序的联接算法。
注:这个简化的合并联接不区分内表或外表;两个表扮演同样的角色。但实际实现方式是不同的,比如当处理重复值时。
- (可选)排序联接运算:两个输入源都按照联接关键字排序。
- 合并联接运算:排序后的输入源合并到一起。
(1) 排序
我们已经说过合并排序,在这里合并排序是个很好的算法。
有些时候数据集已经排序了,比如:
- 如果表内部就是有序的,比如联接条件里有一个索引组织表
- 如果 relation 是联接条件里的一个索引
- 如果联接是作用在一个已经排序的查询的中间结果
(2) 合并联接

这部分与我们说过的合并排序中的合并运算非常相似。区别只在于我们不从两个关系里挑选所有元素,只选相同的元素。
大致原理如下:
- 在两个 relation 里,比较当前元素(当前的等号第一次出现)
- 相同的时候,就把两个元素都放到结果里,再比较两个关系里的下一个元素
- 不相同的话,就去带有最小元素的关系里找下一个元素
- 重复 1、2、3步骤直到其中一个关系的最后一个元素。
因为两个关系都是已排序的,你不再需要「回过头找」,所以这个方法很有效。
这个算法是个简化版本,它没有处理两组数据中相同数据出现多次的情况。
哪个连接算法最好?
如果有最好的,就没必要弄那么多种类型了。由于很多因素要考虑,所以不会有一个简单的答案,需要考虑的因素例如这些:
- 空闲内存大小:没有足够的内存的话,就和有力的哈希联接,至少是完全内存中哈希联接 说bye bye吧。
- 两个数据集的大小:如果一个大表联接一个很小的表,嵌套循环联接就比哈希联接要快,因为后者有创建哈希的成本;如果两个表都非常大,那么嵌套循环联接CPU成本就很高。
- 是否有索引:有两个 B+树索引的话,合并联接似乎是更聪明的选择。
- 结果集是否需要排序:即使你用到的是无序的数据集,你也可能想用成本较高的合并联接(带排序的),因为最终的结果是有序的,你可以把它和另一个结果集通过合并联接合起来(也可能查询用的 ORDER BY/GROUP BY/DISTINCT 等操作符隐式或显式地要求一个排序结果)。
- 关系是否已经排序:这时候合并联接是最佳的选择。
- 联接的类型:是等值联接(比如 tableA.col1 = tableB.col2 )还是内联接?外联接?笛卡尔乘积?或者自联接?有些联接在特定环境下是无法工作的。
- 数据的分布:假如联接条件的数据是倾斜的(比如根据姓氏来联接人,会有很多同姓的人),用哈希联接将是个灾难,因为是哈希函数将产生分布极不均匀的哈希桶。
- 如果你希望联接操作使用多线程或多进程。
相关信息
-



-
-
2023-10-30
windows上的mysql服务突然消失提示10061 Unkonwn error问题及解决方案 -
2023-10-30
MySQL非常重要的日志bin log详解 -
2023-10-30
详解MySQL事务日志redo log
-
-
 MySQL的核心查询语句详解
MySQL的核心查询语句详解一、单表查询 1、排序 2、聚合函数 3、分组 4、limit 二、SQL约束 1、主键约束 2、非空约束 3、唯一约束 4、外键约束 5、默认值 三、多表查询 1、内连接 1)隐式内连接: 2)显式内连接: 2、外连接 1)左外连接 2)右外连接 四...
2023-10-30
-
 Mysql中如何删除表重复数据
Mysql中如何删除表重复数据Mysql删除表重复数据 表里存在唯一主键 没有主键时删除重复数据 Mysql删除表中重复数据并保留一条 准备一张表 用的是mysql8 大家自行更改 创建表并添加四条相同的数据...
2023-10-30
热门系统总排行
- 4754次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 3784次 2 电脑公司ghost win7 64位纯净专业版v2019.08
- 2502次 3 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 2324次 4 深度技术 GHOST WIN10 X64 纯净版 V2019.09(64位)
- 1882次 5 电脑系统城ghost win7 sp132位 经典标准版 V2019.11
- 1794次 6 电脑公司 GHOST XP SP3 安全稳定纯净版 V2019.08
- 1733次 7 电脑公司ghost win7 32位精简旗舰版v2019.08
- 1700次 8 电脑公司 GHOST WIN10 X64 正式专业版 V2019.09(64位)












系统教程栏目
栏目热门教程
- 4949次 1 Mysql实现模糊查询的两种方式(like子句 、正则表达式)
- 3895次 2 一台电脑(windows系统)安装两个版本MYSQL方法步骤
- 2940次 3 DBeaver连接mysql数据库图文教程(超详细)
- 2657次 4 Mysql 5.7 新特性之 json 类型的增删改查操作和用法
- 2395次 5 MySQL无服务及服务无法启动的终极解决方案分享
- 2348次 6 MySQL安装服务时提示:Install/Remove of the Service Denied解决
- 2271次 7 Mysql中find_in_set()函数用法详解以及使用场景
- 2126次 8 银河麒麟V10安装MySQL8.0.28并实现远程访问
- 1951次 9 MySQL8.0 Command Line Client输入密码后出现闪退现象的原因以及解决方法总结
- 1945次 10 Mysql根据一个表的数据更新另一个表数据的SQL写法(三种写法)
人气教程排行
- 56679次 1 联想笔记本进入bios的三种方法 联想笔记本怎么进入bios
- 51285次 2 打印机为什么打印出来是黑的_打印出来纸张表面黑的解决方法
- 39166次 3 笔记本电脑序列号在哪|笔记本电脑序列号怎么看
- 32783次 4 对于目标文件系统文件过大无法复制到u盘怎么解决方法
- 31658次 5 键盘全部按键没反应的解决方法 键盘被锁住按什么键恢复
- 30927次 6 键盘win键无效的解决办法 电脑win键失效怎么办?
- 30837次 7 mac连上wifi却上不了网如何解决 网络没问题但mac无法上网怎么办
- 27301次 8 小马激活工具 Win10正版激活 一键完美激活Win10_小编亲测
- 26439次 9 win7旗舰版激活密钥大全
- 25426次 10 电脑免费的加速器有哪些 永久免费的四款加速器推荐
站长推荐
- 12747次 1 Win11怎么激活?Win11系统永久激活方法汇总(附激活码)
- 6277次 2 联想拯救者win10一键恢复如何使用_联想win10一键还原孔使用方法
- 5819次 3 如何用u盘装系统?用系统城U盘启动制作盘安装Win10系统教程
- 5116次 4 怎么在u盘pe下给电脑系统安装ahci驱动
- 4682次 5 联想电脑开机出现PXE-MOF:Exiting Intel PXE ROM怎么解决
- 3948次 6 华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法
- 3173次 7 win10怎么改为uefi启动_win10系统设置uefi启动模式的方法
- 1926次 8 CentOS 8 系统图形化安装教程(超详细)
- 1876次 9 win10系统下检测不到独立显卡如何解决
- 1850次 10 VMware中安装Linux系统(Redhat8)及虚拟机的网络配置方法
热门系统下载
- 4754次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 4626次 2 Windows Server 2019 官方原版系统64位系统下载
- 4322次 3 网吧游戏专用Win7 Sp1 64位免激活旗舰版 V2021.05
- 4248次 4 Windows Server 2008 简体中文官方原版32位系统下载
- 3944次 5 Windows Server 2008 R2 简体中文官方原版64位系统下载
- 3784次 6 电脑公司ghost win7 64位纯净专业版v2019.08
- 3617次 7 电脑公司ghost win10 64位游戏专用精简网吧版v2020.05
- 3569次 8 Windows Server 2012 R2 官方原版系统64位系统下载